


You’ve got an autonomous Site Reliabilty Engineer (SRE) agent in production. It’s responsive, scalable, and technically sound. But what’s the cost per action — is it worth the token spend? In this edition of our Agentic SRE series, Misha breaks down the economics of autonomy, and how SRE agent performance stacks up against human engineers...
So far, we've followed a clear progression: from building a chess-playing agent to creating an SRE agent that can diagnose production issues on its own. We've shown it works technically, but now we need to answer the million-dollar question: does it make financial sense?
But capability is only half the equation. As any engineering leader knows, the critical question that determines whether a technology moves from research to deployment is simple: Is it economically viable?
Unlike traditional software that incurs primarily fixed costs, LLM-based agents introduce a new economic model where each "cognitive operation" carries a direct, measurable cost. Every token processed, every reasoning step, every tool invocation adds to the bill. At scale, these costs can accumulate rapidly.
In this post, we'll conduct analysis of our autonomous SRE agent to determine if and when such systems make financial sense. We'll examine:
- Cost components: What contributes to the total cost of running an autonomous agent?
- Self-hosted alternatives: Could running our own models reduce costs?
- Scaling considerations: How do costs change as we scale from handling a few incidents to hundreds?
- Optimisation techniques: Our journey to reduce per-incident costs by 83%
- Human comparison: How agent economics compare to traditional human SRE teams
The economics of autonomous SRE look quite different to traditional software, and there's a clear path forward for organisations wanting to dip their toes into this technology. Let's dive in.
The Cost Components of Autonomous Agents
First and foremost, we need to break down the costs of running AI agents, taking our SRE agent as an example. As we'll see, the costs are fundamentally different from traditional infrastructure expenses and require a new approach to budgeting and optimisation.
LLM API Costs: The Primary Expense
Let's start with the biggest cost driver: the LLM itself. We used Anthropic's Claude for our agent, which charges based on tokens processed:
- Input tokens: $3 per million tokens
- Output tokens: $15 per million tokens
For a typical incident diagnosis, our agent used:
With this usage, a single diagnosis costs:
This typical scenario serves as our baseline for analysis throughout this article. While $0.385 might seem a trivial cost for a single incident, consider an enterprise environment with hundreds of alerts daily. At that scale, the costs become substantial.
Token Breakdown
So what's eating up all those tokens? Here's what a typical troubleshooting workflow looked like:
The largest token consumption came from:
- Tool descriptions: ~9,000 tokens
- Conversation history: Growing with each interaction
- Tool responses: Especially log data and file contents
Infrastructure Costs: The Foundation
Beyond the LLM, we needed somewhere to run our agent and its tools. We set up a lightweight Kubernetes cluster on AWS using a single t3.medium instance, costing about $0.0418 per hour ($30 per month). This modest server hosts both the agent itself and the crucial MCP servers that serve as bridges between the agent and the systems it needs to monitor and diagnose.
The full AWS deployment includes a few other necessities: Elastic Container Registry (ECR) for storing our container images, CloudWatch for logs and monitoring, and load balancer for routing. These additional services added approximately $50-70 monthly to our bill. In total, we're looking at roughly $100 per month in infrastructure costs to maintain the entire agent system.
Most MCP servers are primarily I/O bound - they spend most of their time waiting for API responses rather than doing heavy computation. This means we can pack several of them onto a single modest server without performance issues. For a production environment, you'd want more redundancy and perhaps dedicated instances for compute-intensive tasks, but the core infrastructure remains affordable.
Total Cost Perspective
In a hypothetical scenario of 10 incidents per day (a proof of concept) or 300 incidents per month, the total cost would be:
- Infrastructure: $100 as a fixed cost
- LLM API: $0.39 per action, or ~$117 per month
- Total: $217 per month
The key takeaway here is that the main cost driver for our agent is the LLM API, and the infrastructure costs are relatively minor. And the LLM API costs grow linearly with the number of actions, while the infrastructure costs stay constant for a while (until we need to scale up the number of MCP server instances, and even then, the LLM API costs will grow much quicker).
Cost Optimisations Case Study
A single incident diagnosis cost nearly $0.40 in LLM API charges alone. At scale, this would quickly become prohibitive for many organisations. We needed to optimise.
We found three optimisation techniques that, when combined, slashed our costs by a remarkable 83%. Here's the playbook:
Technique #1: Selective Tool Access
Our first agent version had access to every tool we had, just in case it might need them. However, each tool description adds tokens to the context window, and with all tools available, we were sending about 9,000 tokens per message, 72,000 tokens per action. With the input tokens costing $3 per million, that's $0.216 per action on tool descriptions alone.
Our initial implementation exposed all available tools to the agent. While this maximized flexibility, it came at a significant cost. Each tool description added to the context window increased token usage and therefore API costs.
The fix was simple but effective: only provide tools the agent actually needs for the current task. We made the agent configurable, so we could limit which tools it could use, bringing our input tokens down to around 53,000 - less than half the original amount.
This one change dropped our per-diagnosis cost from $0.385 to $0.184, a 52% reduction without changing a single line of agent logic itself.
Technique #2: Stop Repeating Yourself (Tool Caching)
Next, we noticed something obvious in hindsight - we were sending the same tool descriptions over and over with every LLM call. Why not cache them?
Reading from the cache is much cheaper than providing input tokens, and we only pay for the cache write once:
- Cache read: $0.3 per million tokens
- Cache write: $3.75 per million tokens
- Input tokens: $3 per million tokens
We implemented tool description caching using Anthropic's cache system. On the first call, we store the lengthy tool descriptions. For all subsequent calls, we just reference them.
This cut our costs by another 39%:
Not bad, but we weren't done yet.
Technique #3: Remember Everything (Conversation Caching)
Our biggest breakthrough came when we started caching the entire conversation context, not just tool descriptions.
Instead of sending the growing conversation history with each call, we store it in Anthropic's cache and only send new information. This brought our input tokens down to almost nothing - just 32 tokens for an entire diagnosis sequence that previously used 124,627 tokens!
The results speak for themselves:
The Magic Combination
When we combined all three techniques - selective tools + tool caching + full conversation caching - the savings were dramatic:
That's right - just 6.7 cents per incident diagnosis. At that price, you could run thousands of automated diagnoses for the cost of a single human engineer's hour.
There's more we could optimise - better prompt engineering, filtering large outputs before passing them to the LLM, using smaller models for simpler subtasks - but the techniques above gave us a solid foundation.
Comparison to Self-Hosted LLMs
A natural question would be "Why not just host our own LLM?" After all, there are plenty of open-source models available that seem like they could do the job without recurring API costs. Let's look at the numbers.
We can compared two options against our Claude-based agent: a smaller model (Mistral 7B) and a larger one (Mistral Large 2). Both were heavily quantized to run on reasonable hardware.
Option 1: Small But Speedy (Mistral 7B)
We ran Mistral 7B on a g5.2xlarge AWS instance ($1.21/hour) with GPTQ quantization. This setup processes input tokens at about 2,500 per second and generates output at roughly 250 tokens per second.
For the same diagnosis task we measured earlier it would take:
- Processing input: ~21 seconds
- Generating output: ~7 seconds
- Total time: ~28 seconds per diagnosis
This means we could theoretically handle 128 incidents per hour, bringing the cost per incident down to just $0.01 - cheaper than our optimized Claude setup.
But there's a catch (actually, a couple of them):
- This price only works if you're running diagnoses 24/7 - any idle time drives the cost per action way up
- Mistral 7B struggles with complex reasoning compared to Claude
Option 2: Bigger But Slower (Mistral Large 2)
We also estimated the cost of Mistral Large 2 (123B parameters) running on a g5.12xlarge instance ($5.67/hour); the smallest instance on AWS that would theoretically run it. This model was quantized to IQ2_M to fit in the available memory.
This setup is much slower:
- Processing input: ~9 minutes
- Generating output: ~2.5 minutes
- Total time: ~11.5 minutes per diagnosis
That means we could only handle about 5 incidents per hour, pushing the cost up to $1.05 per incident - significantly more expensive than Claude. On top of that, the quality of the resulting diagnoses is likely to be worse, as the model is smaller than Claude, and is heavily quantized on top of that.
Overall Comparison
The economics of self-hosting completely fall apart at low utilisation.
Software incidents typically don't arrive on a neat schedule. They spike, they cluster, they may not happen for hours and days. This unpredictable pattern is exactly where pay-as-you-go API services shine, and self-hosting may not be economically viable.
Furthermore, the smaller models are more likely to miss the mark on complex issues. They'd misinterpret logs, suggest irrelevant fixes, or fail to use tools effectively. These errors would required human intervention, negating any cost savings.
Self-hosting however may be economically viable for other use cases, when:
- You have constant flow of data that needs to be processed by an agent
- You're working with sensitive data that can't leave your infrastructure
- You're running non-urgent diagnostics that can be batched together, and only spin up the LLM when needed
Scaling Considerations and Rate Limits
As autonomous agents move from experimental to production environments, scaling dynamics become critical cost factors. How many incidents can be diagnosed simultaneously, and what are the implications for real-world deployments?
So you've optimised your agent costs and you're ready to scale up. But what happens when your beautiful system hits the wall of rate limits and throughput constraints? Let's talk about what it takes to move from handling a few test incidents to running a full production deployment.
API Limits: The Ceiling on Your Growth
Our first practical concern was Anthropic API rate limits. Here's what they look like for Claude:
When we first deployed our agent and started running real-world tests, we quickly discovered which of these limits actually matters. With our optimised agent using caching, we weren't even close to hitting the token rate limits. The real constraint was simply our monthly budget cap.
For perspective, even our modest Tier 2 budget would let us diagnose over 500 incidents per month at our cost of $0.067 per incident. That's more than enough for many mid-sized engineering teams that might face 10-20 incidents per day.
The Economics of Self-Hosting at Scale
What about running your own models as you scale? We ran the numbers:
The catch? These numbers assume 100% utilisation - your model running non-stop, 24/7. But incidents don't work that way. They spike during deployments, cluster during outages, and may disappear for days.
For a team handling 500 incidents monthly, those 28-second Mistral 7B diagnoses would only keep your server busy for 3.9 hours. The rest of the time, you'd be paying for an idle GPU. Your actual cost per diagnosis? Not the theoretical $0.01, but closer to $1.74 - over 25 times more expensive than our Claude solution.
Infrastructure Scaling: How Your Support Systems Grow
As you scale, you're not just sending more requests to an LLM. You're running more MCP servers (our tool interfaces), making more API calls, and potentially stressing other systems.
The good news is that MCP servers are primarily I/O bound - they spend most of their time waiting for responses from external systems like Kubernetes or GitHub. Our modest t3.medium instance ($30/month) could comfortably handle dozens of concurrent tool servers without issues.
But there are three important scaling considerations:
- Tool explosion: More systems to monitor and more capabilities we want to add to the agent, means more tools, which means larger prompts. When we add a dozen new MCP servers, our prompt size grows quite quickly, increasing our per-action costs, and potentially reducing agent's performance.
- Downstream API limits: Even though for the cases we explored we are nowhere near the limits of the APIs we are using, there's still a risk of being constrained by limits of other APIs we might want to add in the future.
- Large computations: As already mentioned, our MCP servers are not compute-bound, but for some other use cases you might need to run some heavy computations. In that case you might need to consider scaling up to a more powerful instance.
Comparison with Humans
When evaluating the economic feasibility of autonomous SRE agents, the most important comparison is against the traditional alternative: human SREs. To make this comparison meaningful, we need to consider both direct costs and the broader value proposition.
Let's start with the raw numbers. Here are the assumptions we're working with:
Human SRE Engineer:
- Average annual salary: $100,000 (depending on location and experience; we use median for London)
- Hourly rate: $50 (based on ~2,000 working hours per year)
- Benefits, office space, equipment: ~30% additional cost
- Effective hourly cost: $65
Time Assumptions:
- Average time for human to diagnose an incident: 15 minutes; as estimated in the previous blogpost
- Average time to review and verify agent's diagnosis: 2 minutes; not a direct measure, but sounds sensible for our hypothetical SRE engineer
What does this mean in practice? A human solving a problem takes about 15 minutes, costing $16.25 per incident. When the agent handles it with human verification, you're looking at just $2.23 ($0.067 for the agent + $2.17 for the 2-minute human check).
But here's the catch - agents won't nail every diagnosis. Sometimes they'll miss, and a human will need to step in and solve the problem from scratch. So how often does the agent need to get it right to make economic sense?
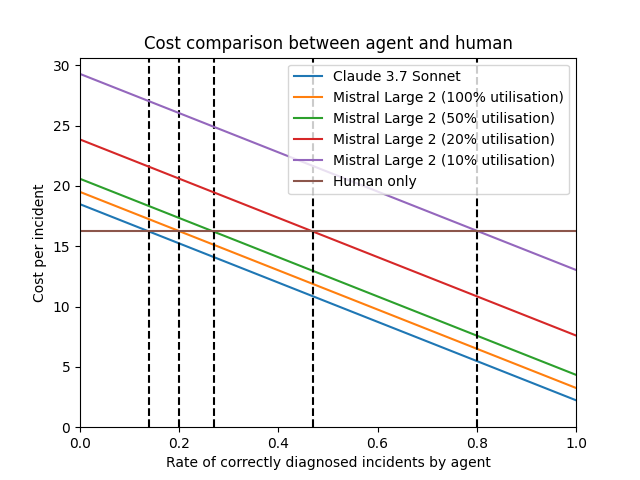
The graph makes it clear. Our Claude-based agent (blue line) becomes cheaper than the human-only approach (brown line) when it correctly handles just 15% of incidents. That's a really low bar!
Self-hosted Mistral Large 2 tells a different story. At perfect utilisation (orange line), it's nearly as good as Claude. But at more realistic utilisation rates like 10% (purple line), the model would need to be right around 80% of the time just to break even.
Beyond Cost: The Total Value Proposition
The true economic impact extends beyond direct cost comparisons:
- Response time: Autonomous agents can begin diagnosis immediately, reducing mean time to resolution (MTTR)
- Consistency: Agents apply the same thorough approach to every incident
- Knowledge retention: Unlike human teams that experience turnover and knowledge loss, agents maintain complete system knowledge
- 24/7 availability: No off-hours, holidays, or vacation coverage concerns
- Team leverage: Human SREs can focus on high-value work instead of routine diagnostics
When factoring in these benefits, the economic case for autonomous SRE agents becomes even stronger. By reducing downtime costs and freeing human engineers for innovation, the total organisational value significantly exceeds the direct cost savings.
The most effective approach is likely a hybrid model - let agents handle the common, well-understood incidents while human engineers focus on novel issues and system improvements. This approach maximises cost efficiency while ensuring all incidents get resolved appropriately.
Of course, these numbers are a simplified view of reality. Our analysis uses reasonable assumptions based on available data, but your actual mileage will vary depending on team size, incident frequency, and the specific technology stack you're monitoring. Think of this more as a framework for understanding the tradeoffs rather than an exact prediction. Despite these limitations, the core takeaway remains solid - autonomous SRE agents hit a favorable economic threshold at surprisingly low success rates, making them worth serious consideration for many teams.
Autonomous SRE agents are already hitting a favourable economic threshold — even at modest success rates. That alone makes them worth a serious look for teams thinking about scale, cost, and response time.
This post is a snapshot — Misha’s take at the time of writing, built on solid assumptions and current models. But things are moving quickly. New entrants like Kimi 2.0 are already changing the maths, often in ways that make autonomy more accessible, not less. So while this isn’t a final answer, it’s a strong starting point — a way to think clearly about trade-offs before the next update lands.
The tech is evolving fast, and the future’s still rendering.
.png)





Sign up to our newsletter

Heron House
1 Lincoln Square, Manchester
England, M2 5LN
0161 533 0337