

.jpg)
Co-written by Jon Carlton
You can find the first blog in our series, MindGPT: An introduction, here.
Everything in machine learning starts with data. That’s true whether you’re building a Large Language Model, or something a bit smaller. Getting data right early on saves us a great deal of pain further down the road.
In this blog we explore the role of DataOps and data pipelines in our project MindGPT, a large language model for mental health. We’re gathering data from two sources — Mind, and NHS Mental Health — and using that to create an intelligent agent that can answer mental health questions, synthesising information from both sources.
This blog forms part of a series on MindGPT, in which we’re sharing our journey as we build a specialised LLM for mental health information. Each blog will highlight the technical details of a particular stage in the development of a custom LLM. For a more in-depth project introduction, see Jon’s blog. To see exactly what we're building, check out the GitHub repository.
Through this project we’re going to be demonstrating how with entirely open source tools and models, it’s possible to create your own LLM, as well as showing why open source is so pivotal to making these LLMs explainable and trustworthy.
So, what is DataOps?
Admittedly the word DataOps isn’t quite as trendy as MLOps, not to mention LLMOps (Large Language Model Operations), which has now taken centre stage. DataOps is all about breaking down the process of gathering, cleaning, and preparing data into steps that are repeatable pipelines.
To understand what that means for MindGPT, let’s think about our goal. We want to take a pre-trained large language model, and teach it to answer a user’s questions about a specific topic, mental health. We’ll use two data sources (NHS and Mind), and we’ll acquire data through web scraping which, while at times a bit fiddly, isn’t too challenging.
So far, so good. But as we start to imagine about how we’ll maintain this model in production over an extended period of time, a few challenges come to mind:
Data refreshes: the information on the source websites gets updated from time to time. We’ll need a robust, repeatable process for updating our data when that happens, and we want to ensure that each step of the process is expressed as code, with unit tests.
Versioning: we’ll need to keep track of different data versions. More specifically, we want to track when data was scraped. This way, for any answer our model gives, we’ll be able to say exactly what sources it used, including the time and date of scraping.
Cleaning: cleaning text data can be challenging. We’ll need to remove extraneous characters, whitespace, and stray HTML tags, among other things.
Validation: when we create our model, we’re inevitably going to make certain assumptions about the data. This ranges from obvious things, like “data values are not null” all the way to “this particular numerical value is normally distributed, with such-and-such mean and standard deviation”.
Training a model on new data without first validating those assumptions is a waste of time. If the key data characteristics that you’re relying on have changed, then your model will likely be wrong.
Text data isn’t as simple to validate as numerical data. However, we might start by using the average text length as a metric for validation. Getting more sophisticated, we could work within a text embedding space (later on we'll explore that further through vector databases), validating the in-coming cleaned data by checking whether it exists in the same embedding space compared to the previous version. If there’s a drastic difference, i.e., if their position in space has changed, then it could signal that something is wrong with the new data.
Monitoring: in a production setting, we’re expecting to run all of the above in an automated pipeline, perhaps on a schedule, or just whenever one of the source websites makes a change. Just as we monitor ML models, we also need to monitor data pipelines, so we know when data validation fails or something else goes wrong.

DataOps for Large Language Models
With definitions out of the way, let’s take a look at how we’re building data pipelines for MindGPT. The diagram below shows the overall plan for the project, which includes DataOps pipelines, as well as MLOps pipelines for fine tuning and deploying the models, and a front-end web application so that users can interact with the model.
We have separated the various data operations into distinct pipelines: one for data scraping (shown in green), and another for data preparation (shown in orange).
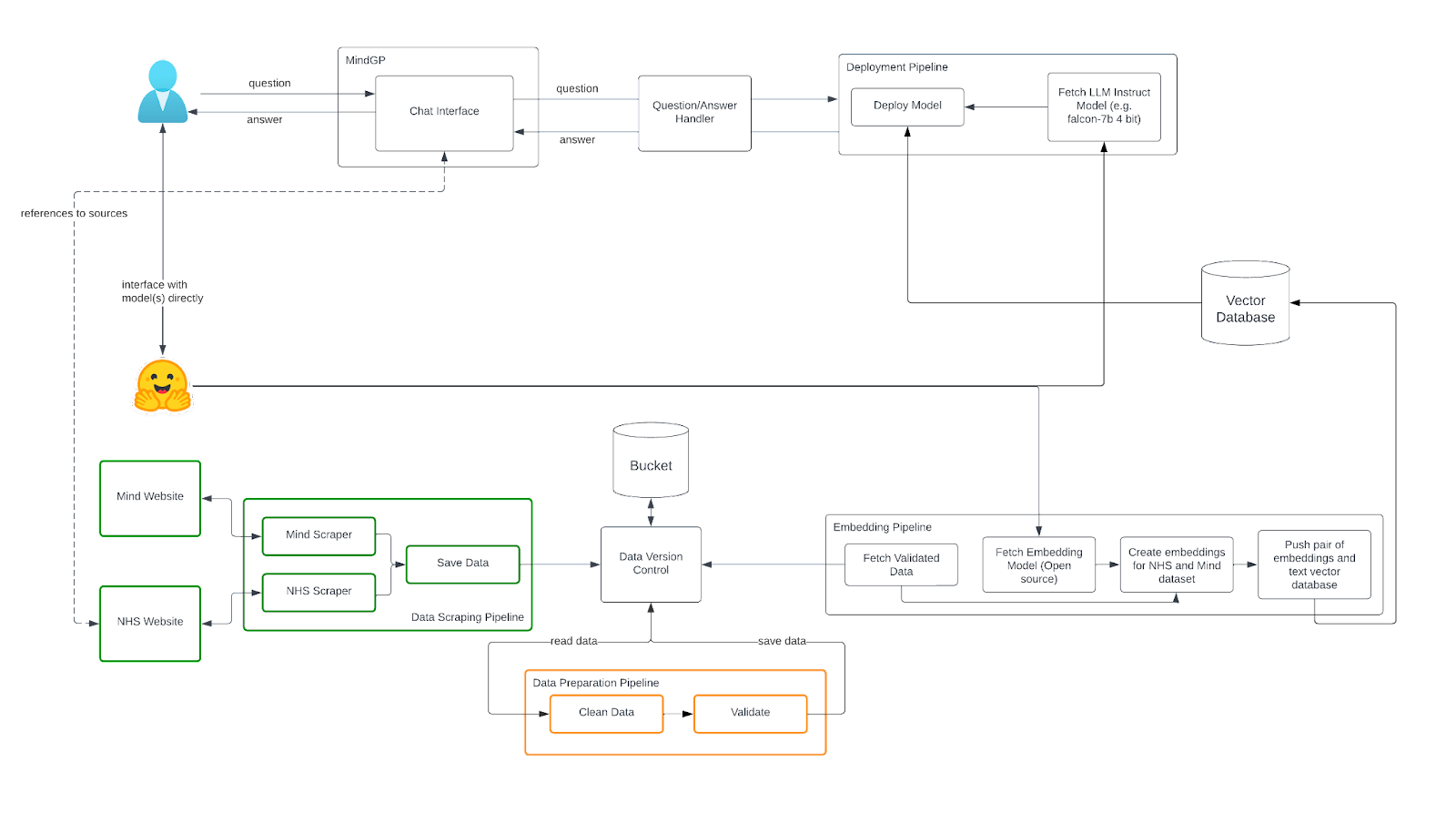
Let’s delve into each of those pipelines in a little more detail. Here at Fuzzy Labs, we’re accustomed to using ZenML (an orchestration tool) to define ML pipelines, but that doesn’t mean that’s the only thing it can be used for — in this project, we’re also using it for our DataOps pipelines.
If you’re not familiar with a tool like ZenML, it’s quite straightforward: functionality is decomposed into steps and a series of steps make up a pipeline which can be executed. Steps within a pipeline can be executed in parallel or sequentially. Where the pipeline is executed is determined by the stack, which defines components used within the pipelines. There’s more that can be said on this topic, but for the purposes of this blog, I’ll point you to some of our existing content.
Starting with the data scraping pipeline (shown in green above), below is what the diagram looks like when converted into a pipeline.<pre><code>@step
def scrape_nhs_data() -> pandas.DataFrame:
...
@step
def scrape_mind_data() -> pandas.DataFrame:
...
@pipeline
def data_scraping_pipeline() -> None:
nhs_data = scrape_nhs_data()
mind_data = scrape_mind_data()</code></pre>
The pipeline is composed of two steps: one for scraping the NHS website and another for scraping the Mind website — we’ll leave the inner workings of these steps out of this blog, but if you’re interested, here’s the project GitHub. The pipeline is defined using the <code>@pipeline</code> decorator, which signals to ZenML that this is a pipeline and not a regular Python function. The same is true for the <code>@step</code> decorator.
You might be wondering where the “save data” part of the pipeline is — it’s in the diagram, but not defined as a step. This is because we’re making use of functionality provided by ZenML: the artifact store, a component of the stack mentioned earlier. This is storage for objects created by your pipelines, and the store could be local or remote (on Azure, for example). When an object is returned by a step, ZenML automatically saves it in the artifact store as output. You’ve probably already figured this out, but it means that we don’t need to explicitly save the data as we can read the data from the store later (the artifact store is shared amongst all pipelines run on the same stack).
Let’s move onto the data preparation pipeline. The aim here is to clean and validate the data. As a pipeline, this is a little more complex compared to the previous in that it has more steps, see below.<pre><code>@pipeline
def data_preparation_pipeline() -> None:
mind_df, nhs_df = load_data()
mind_df = clean_data(mind_df)
nhs_df = clean_data(nhs_df)
mind_df = validate_data(mind_df)
nhs_df = validate_data(nhs_df)</code></pre>
There’s three components to this pipeline: loading the data, cleaning it, and validation. Loading data reads the data from the artifact store (which we saved in the previous pipeline); the <code>clean_data</code> step does what it says on the tin and cleans the data, e.g., removing NaNs and duplicates (if any) and formatting the text scraped from the websites — all standard processes; validation checks that the data is in the format that we expect it to be in and validates that the links associated with each scraped page actually works.
You may have also noticed that data version control isn’t included in either of these pipelines. This is deliberate and it’s something that we’re actively working on including, the goal here was to get the basics up and running first, before introducing additional complexities. We’ll cover this in a future blog post.
Let’s talk more about the sequential and parallel execution of steps in a pipeline.
In the previous pipeline, the scraping steps are executed in parallel, as they’re not dependent on the output of a previous step and the order of execution isn’t enforced. In this pipeline, as the output of previous steps are used as input to subsequent steps, the former has to finish executing before the latter can start. In other words, <code>validate_data</code> cannot happen until <code>clean_data</code> has finished.
What’s interesting here is that while there is a sequential ordering to the groups of steps, the groups themselves are executed in parallel. For example, the two calls to <code>clean_data</code> rely on the <code>load_data</code> step to be finished executing before they start executing (the sequential part), but the execution of the two steps (the two calls to <code>clean_data</code>) happens in parallel. See below for an illustration. This means that the pipeline can be run at scale, making the process much more efficient, saving time, and money even as the dataset grows.
So, to summarise all the above, we’ve covered what DataOps is and how we’re doing DataOps for MindGPT. The project is in active development and there’s plenty more to come and to talk about, and here are some pointers to code that’s been talked about in this blog:
- Data scraping pipeline
- The NHS data scraping step and the Mind data scraping step
- Data preparation pipeline
- The steps that make up the data preparation pipeline
What's next?
As mentioned previously, we’re currently implementing data version control into the pipelines which we’ll talk about at a later date. In our next blog update, we'll discuss vector databases, demonstrating what they are and why they're useful for LLMs, and how we've implemented one in MindGPT.
Stay tuned for updates!
%20(1)%20(1).jpg)





Sign up to our newsletter

Heron House
1 Lincoln Square, Manchester
England, M2 5LN
0161 533 0337