


Machine learning algorithms have infiltrated our daily life even without knowing it with applications such as Alexa, Siri (speech recognition), Netflix (movie recommendation), Amazon (product recommendation), Spotify (music recommendation), YouTube (video recommendation), and many more. Machine learning algorithms are also being used to provide personalised recommendations which adapt to your past behaviour and preferences. Imagine a personalised algorithm which tells you why you should keep watching cat videos (a severe lack of "purr-entertainment" in your daily routine 😻!)
MLOps (Machine Learning Operations) is a set of practices that aims to deploy and maintain machine learning models in production reliably and efficiently. In this blog, we will convince you why and how MLOps play a critical role for any ML application. We create a simple recommendation system application and outline various ways MLOps can help alleviate different problems that we might encounter when deploying this application in production. We explain and demonstrate why and how MLOps is the secret sauce to create a great recommendation system.
ML Recommendation Systems
For the purpose of this blog, consider a scenario where you are tasked with building an ML application that recommends similar products. The job of the ML system is to recommend N similar images based on an input image.
To demonstrate how MLOps can provide value to this ML recommendation system, let’s take a step back and build a simple end-to-end ML system that provides recommendations. We’ll use the Fashion product images dataset, which contains 44,000 images and their corresponding categories. Using this dataset, we’ll apply ML magic 🪄 to recommend similar products to a user. This ML magic will learn a representation from the dataset such that it clusters similar images close together in an embedding space.
Don’t know what embedding space is? Head over to Chris Norman's blog that provides an excellent primer on embedding space.
The task here is to train a deep learning model on the image dataset. Since all images have labels associated with them, we can train a Convolutional Neural Networks (CNN) classification model that takes in input an image and predicts the label as output. To do this, we create a script that takes care of pre-processing the dataset in format required by the model, splits the dataset and training the model. The pseudo code for the training script looks like following
<pre><code>def split_dataset(whole_dataframe):
"""Split entire dataframe into train, val and test dataframe."""
# split dataframe into 80% train - 20% test ratio
# use sklearn.model_selection.train_test_split method to split
return train_df, test_df
def create_dataset(train_df, test_df):
"""Create datasets from dataframe."""
# use tf.keras.preprocessing.image.flow_from_dataframe method
# to read pandas dataframe
# and output tf.data.Dataset for each dataframe
return train_ds, test_ds
def train_model(train_ds, test_ds, num_classes):
"""Train and evaluate a model."""
# create a CNN classification model
model = tf.keras.Sequential([
...,
layers.Dense(256, activation='relu'),
layers.Dense(num_classes, activation='softmax')
])
# create a optimizer and loss function
# perform training and evaluation on datasets
# monitor metrics like loss and accuracy
# save and return best performing model
return model</pre></code>
Once we have trained the model and are satisfied with the performance on the test dataset, we are ready to extract the embeddings. To extract embeddings from a trained model – especially for CNN architectures with two dense layers at the end – we get the output of the model from the penultimate dense layer for a given input image. The penultimate, fully-connected layer typically has a higher dimensionality (in this case 256) than the final dense layer (in this case equal to number of classes), which means that it captures more information. Hence, we use the penultimate layer instead of the final layer of the model for extracting embeddings. This approach is not unique. It varies for different architectures (e.g. encoder-decoder, using pooling layers) and can have variations for extracting embeddings.
The pseudo code to extract and store embeddings looks like this:
<pre><code>embed_model = tf.keras.models.Model(inputs=model.input,
outputs=model.layers[-2].output)
def extract_embeddings(img_path, embed_model):
"""Extract embeddings for a particular input."""
# preprocess input
# pass input to model to get embeddings as output
# normalize the embeddings
return normlized_embeddings
def save_image_paths_to_file(img_paths):
"""Save image paths to pickle file."""
# create a list of absolute path to all images
# save absolute path to images in a pickle file
pickle.dump(img_files, open("img_files.pkl", "wb"))
def save_embeddings_to_file(img_paths, embed_model):
"""Save all embeddings for entire dataset to pickle file."""
# create a list containing embeddings of all images
# save all embeddings of all images in a pickle file
pickle.dump(embeddings, open("embeddings.pkl", "wb"))</pre></code>
Now to the final part of our ML application which is to create a recommendation engine. To get similar recommendations, we use the nearest neighbours approach. The code to get recommendations looks like following
<pre><code># load the saved embeddings of entire dataset
embeddings = pickle.load(open("embeddings.pkl", "rb"))
# load saved path to images of entire dataset
img_files = pickle.load(open("img_files.pkl", "rb"))
def recommend_similar_images(input_embedings, embeddings):
"""Recommend 5 nearest neighbours for given input feature."""
neighbours = sklearn.neighbors.NearestNeighbors(n_neighbors=5, algorithm='brute', metric='euclidean')
neighbours.fit(embeddings)
distance, indices = neighbours.kneighbors([input_embedings])
return indices
def recommendation_engine(input_img_path):
"""Recommend and display 5 similar images to input image."""
# show input image
display_image(input_img_path)
# extract embeddings for input image
out_embeddings = extract_embeddings(input_img_path, embed_model)
# get indexes of 5 similar images
similar_img_indexes = recommend_similar_images(out_embeddings, embeddings)
# show 5 similar images to input image
for ind in similar_img_indexes:
display_image(img_files[ind])</pre></code>
Summarising our simple ML recommendation application,
- We found a appropriate dataset suitable for the task
- Created a script to preprocess dataset in format suitable for training model and trained a CNN model
- Extracted and saved embeddings for whole dataset using the trained model
- Created a recommendation engine to recommend 5 similar images given an input image using trained model and saved embeddings
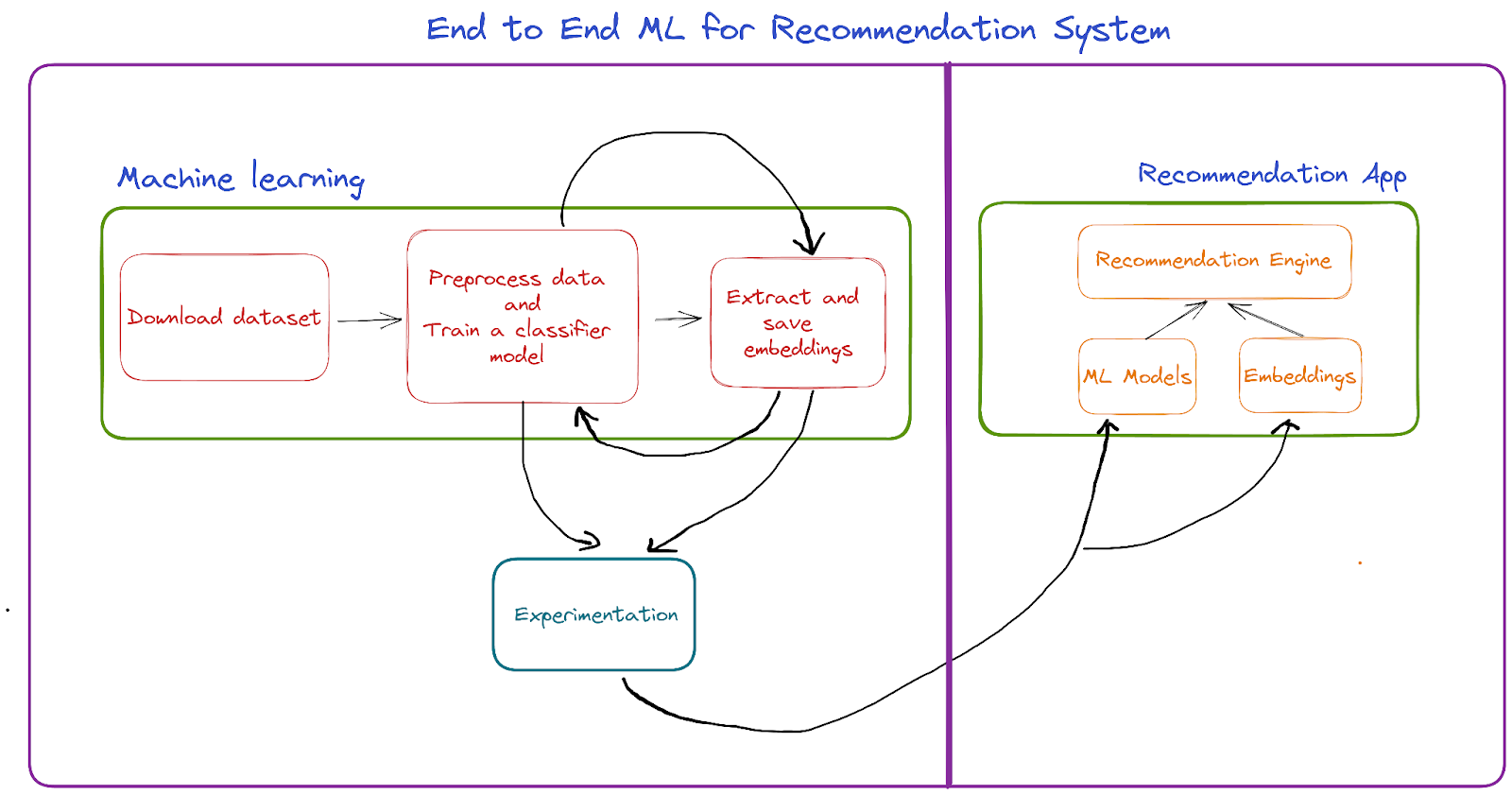
MLOps in ML Recommendation Systems
How can MLOps upgrade this ML recommendation application? MLOps provides a framework for building, testing, deploying and monitoring ML models in a consistent, repeatable and scalable manner (try saying that ten times faster 😛). MLOps tools can be used to address the following areas that are missing from our application.
- Machine learning pipelines and Test driven development
- Data provenance and versioning
- Data validation
- Experiment tracking
- Model validation
- Model provenance and versioning
- Model registry
- Reproducibility
- Feature stores
- Model deployment and serving
- Model monitoring
In the following section, we examine each area in great detail and answer the questions why it is required and how it can help our ML recommendation application.
At FuzzyLabs, we have curated a list of open source MLOps tools that covers all the areas mentioned above and many more. If we've missed any open source tools, please do raise a pull request here.
Machine learning pipelines and Test driven development
Why?
All machine learning projects should follow a pipeline based workflow. Data scientists prefer using notebooks for experimenting and creating initial proof of concepts. This approach cannot be easily scaled to production. A pipeline consists of multiple steps where each step can be unit tested. A step can be thought of as solving a particular machine learning problem. For example, a data pipeline contains a step for reading data, a step to convert it into a proper format, a step for data cleaning, a step for data validation, etc. Steps can have dependencies where steps might use the output of the previous step. Multiple pipelines can be created for different purposes. For example, a data pipeline for creating a good quality dataset, a training pipeline for training and evaluating models, and a deployment pipeline to serve the models. This MLOps pipeline-oriented approach makes it easy to perform fast iterations and deploy projects to production faster. Writing tests for each step and entire pipeline will ensure the correctness of individual components and whether different components work with each other in our ML pipelines. A Test Driven Development (TDD) approach will help us catch bugs early in the development cycle.
How?
Pipelines help us break down a complex ML project. In our application, we created a single training script that took care of reading and preprocessing the dataset, as well as creating, training and evaluating the model. Using the pipelines workflow, we could have created 4 pipelines i.e., data pipeline, training pipeline, inference pipeline and deployment pipeline. Data pipeline consists of steps such as reading the dataset, cleaning the dataset, validating the dataset. The output of this pipeline is a dataset that is validated and in correct format. The training pipeline consists of steps such as splitting the dataset, creating, training and evaluating model, and performing model validation. The inference pipeline consists of a single step to extract embeddings for the entire dataset. Finally, our deployment pipeline consists of a step to serve both the trained model and embeddings for the entire dataset. A separate recommendation application can query the trained model to get the embeddings for our input image and a nearest neighbour approach can find the indexes closest to a newly calculated embedding and embeddings of the entire dataset. Popular open source tools include ZenML and Kubeflow.
Data provenance and versioning
Why?
Data provenance is a trail which provides a record of the data origin. Data provenance involves tracking all the processes and systems that influence the data. It answers questions such as 'Where did the data come from?', 'What steps were taken for cleaning and transforming the data?', 'Who was involved?', 'What version of the code was used to get the final data?', and 'What data validation checks did the data pass?' This process makes it easy to recreate any model by providing a trace back to origin as to what data was used. Data versioning involves keeping track of multiple versions of data. Throughout the MLOps project, the dataset is never static. It keeps growing as we keep collecting more data from increased use of the ML application. Data versioning tools keep track of these changes.
How?
For our application, keeping track of data is of paramount importance. This problem becomes clear once we start working across multiple ML projects and multiple teams. It is easy to keep track of one or two projects using spreadsheets, but once a team starts growing this system breaks fast. Hence, it is important to start using these tools early on in the project for debugging and accountability in responsible machine learning. Popular open source tools include DVC and pachyderm.
Data validation
Why?
ML projects often require large amounts of data. Data validation process involves monitoring the quality of data fed to machine learning algorithms. There is a quote that highlights the importance of data passed to training the models, “garbage in, garbage out”. If the quality of data is poor, the performance of the model will be equally poor. These tools can help catch the inconsistencies in the dataset such as label issues, duplicate examples, and detecting anomalies, before training a model using the flawed dataset.
How?
For our ML recommendation application, the dataset consists of images. Data validation tools can help us catch inconsistencies such as invalid format, anomalies in sharpness, brightness, and corruption in images. Popular open source tools include cleanlab, Great Expectations, and Deepchecks.
Experiment tracking
Why?
MLOps projects require a lot of iteration that involves tuning many hyper-parameters to get a good model. Experiment tracking tools keep track of different ML experiments and log various components such as parameters, metrics, model artifacts, code version, and data version. It helps monitor performance of the current model and compare it against all the previous experiments. Experiment tracking also ensures the results of a particular model are reproducible. To enable us to track, share and reproduce all the experiments easily, we should use experiment tracking tools.
How?
For our ML recommendation application, we can track the performance of our ML models. We can also log and visualise the results on the test dataset. Experiment tracking will enable us to quickly compare experiments with different model architectures. Popular open source tools include MLFlow, Tensorboard, and Guild.AI.
Model validation
Why?
Model validation is the process of validating the output from a trained model makes sense. This process consists of checklists such as model test accuracy passes some threshold, the performance of the model does not vary across classes, the model is robust against adversarial attacks, and identifies the model’s weakest segments. Model validation will help us catch the “silent error” in ML projects where the model is performing well on the dataset but not performing well when deployed in production, before even deploying the model.
How?
In our application, some important validation includes assessing the diversity, fairness and popularity bias in the recommender system. Validating models on metrics such as nDGC@k, Recall@k, hit-rate, and many more that are tailored towards measuring the success of recommendation systems. Popular open source tools include Trubrics and Deepchecks.
Model provenance and versioning
Why?
Similar to data provenance and versioning, model provenance and versioning are important for ML projects. Model provenance helps us answer questions such as can we reproduce the same training results and model if we repeat the training process? What was the version of the machine-learning library and code that was used? What hyperparameters were used? What was training data? What augmentation techniques were used and how did they transform the data? Did the model pass all the model validation checks? Model versioning tools provide a way to keep track of trained models. MLOps projects involve a lot of experimentation, tinkering hyper-parameters, until we get a good model. These tools help keep track of all the models across various experiments making it easy to compare, share, deploy and reproduce the best model.
How?
For our application, many experiment tracking tools also provide these features. Versioning and provenance tracking are important for debugging and accountability in responsible machine learning. Popular open source tools include MLFlow and Bailo.
Model registry
Why?
Similar to model versioning, model registry refers to a central repository that acts as a Version Control for machine learning models. These registry tools should be generic and work for any ML model format. The models stored can be versioned to easily track the performance of the same model across various sizes of dataset. Model registry also encourages team collaboration where each team member can try and register their own versions of models. The best performing model can be pulled from the model registry for deploying in production.
How?
For our application, adding a model registry would provide a way to fetch and store ML models easily. Many experiment tracking tools also provide model registry as a feature. Popular open source tools include MLFlow, Bailo, DVC, and modelstore.
Reproducibility
Why?
The machine learning field is often plagued with reproducibility and replicability issues. Reproducibility means we can replicate any experiment and get the same results each time. Versioning is one way that we can achieve this, along with using dependency management tools. Addressing areas such as data and model provenance, code, data and model versioning should help address the reproducibility issues.
How?
For our application, it is essential that we can reproduce the same application anytime. To tackle reproducibility we should address all the different areas in the MLOps workflow above. Popular tools such as envd can be used for reproducing AI/ML environments.
Feature stores
Why?
Feature stores allow an easy way to share and store features across MLOps pipeline. Feature stores provide consistency, versioning, and validation to the stored features. These stores also act as a lineage for features. There are two kinds of ML features: online and offline. Online features are dynamic and have a requirement to be processed in near real-time everytime. Offline features are often processed in batches as they don’t change much.
How?
In our recommendation application, we extract the embeddings for the entire dataset. We store these embeddings to a pickle file. This file is used by the recommendation engine to read and load the embeddings, and find nearest neighbours. A better approach would be to save these embeddings to a feature store. This will avoid the problem of using stale embeddings, i.e., embeddings being inconsistent with the deployed model. The recommendation application can also connect to the feature store to access the pre-computed embeddings required for calculating nearest neighbours. Popular open source tools include Feast, Hopsworks, and Feathr.
Model deployment and serving
Why?
Once we are happy with model performance, it is time to deploy this model. There are various patterns that we can use to deploy a ML model depending on the application. Is it a batch prediction model or should predictions be generated in real time? One of the popular patterns include Model-as-Service where a trained model is presented behind a REST API or GRPC service endpoint. The application can make use of these endpoints to send input data and get back the predictions from the model.
How?
For our application, we read and load the trained model, read and load the saved pickle files containing embeddings for creating a recommendation engine. This approach is not scalable and might fail in many ways. An alternative approach is, we could write a simple web application with our recommendation engine that uses the endpoint where our ML model is deployed and a feature store for accessing pre-computed embeddings. This approach will be scalable and robust. There are many open source tools designed to tackle this area. Popular tools include Seldon Core, BentoML, and Bodywork.
Model monitoring
Why?
Monitoring means making sure that each deployed model is both functioning, and producing sensible results. In traditional software engineering, the majority of work is done in initial stages and in deployment it works as we defined it. In MLOps, there is much work to be done after the model is deployed. This is covered in the ML monitoring phase. Model monitoring includes monitoring concept drift, data drift, monitor model biases and degradation of model performance over time for any ML application. Model monitoring helps catch the silent errors in ML applications where model performance degrades over time. Model monitoring focuses not only ML metrics but also keeping track of system metrics. This includes checking the availability/uptime, latency, throughput, CPU/GPU utilisation, memory utilisation, the number of prediction requests your model receives in the last minute, hour, day, and, the percentage of requests that return with a 2XX code. No matter how good your application is, if the system is down, there is no use for the application.
How?
Model monitoring is useful for our application to get insights on how the model is behaving after it is deployed. Some advanced metrics to monitor related to business would be Click-Through Rate, Conversion, Revenue generated, etc. The application can be improved as we start to get more insights on cases where it is failing. Recommender systems usually have a slow feedback loop. We also have to be careful about degenerate feedback loops created by relying on click-through-rate predictions. Degenerate feedback loops are created when a most clicked item is recommended multiple times, making it popular. This phenomenon goes by many names such as “exposure bias”, “popularity bias”, “filter bubbles,” and sometimes “echo chambers”. A way to tackle this is measuring the popularity diversity of the system's outputs. Popular tools include Evidently, Alibi Detect, and RecList.
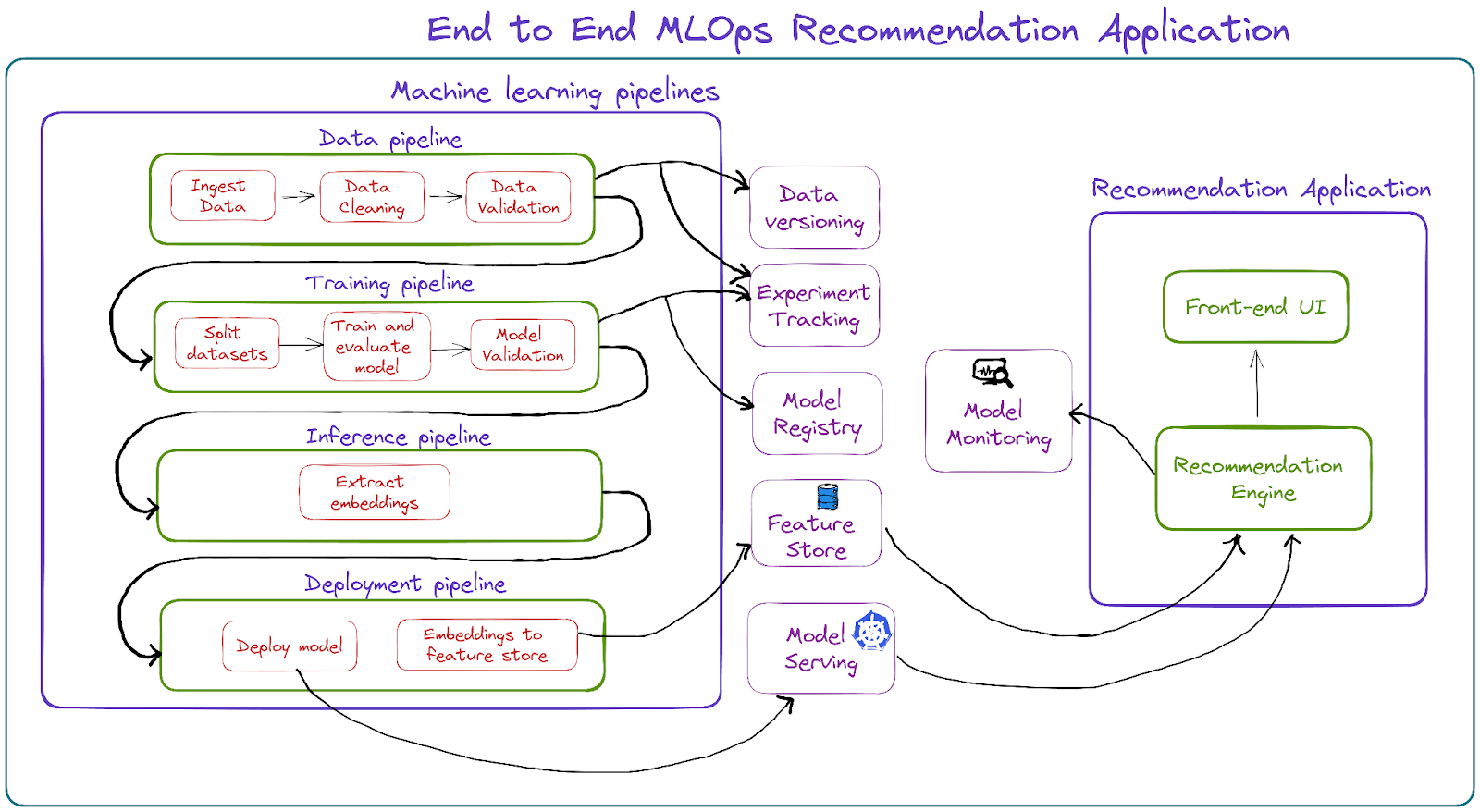
Conclusion
In this blog, we created a simple end-to-end ML application recommendation system that provides recommendations for similar images for given input images. We sketched the process required to create a recommendation engine by providing pseudo code for all the steps involved. The steps were:
- ingesting and preprocessing the data
- training and evaluate the model using the pre-processed data
- extract embeddings for entire dataset
- finally use the extracted embeddings and trained model to create a recommendation engine
After creating the application, we wondered if the end-to-end ML approach was sufficiently scalable and reproducible to deploy this application in the real-world. We found several flaws in the existing approach and looked at how MLOps can be used to address these flaws. MLOps workflow detail why and how addressing 11 different areas could upgrade this ML application to create an efficient, scalable, reliable, and reproducible ML recommendation system. These 11 areas, part of the MLOps workflow, are generic and can be applied to any existing ML application.
%20(1).jpg)
.png)



Sign up to our newsletter

Heron House
1 Lincoln Square, Manchester
England, M2 5LN
0161 533 0337